Did my swanky new shoes CAUSE my PB?
Last Saturday, I put on my new running shoes and ran my Parkrun PB. This has been my brag post, thanks for coming to my TED talk, see you later.
Okay sorry that was silly… but I promise, there is a point to this.
The question is, was this down to the new shoes? Was it my ‘intervention’ that caused the success?
It’s your classic evaluation question.

Considering context
I’ve signed up to the Robin Hood Half Marathon in September. It’s my first half, and I’m nervous, so I’ve been running consistently for a while now. You could call it a running plan, although I call it “why am I doing this to myself for longer each time?”
My old shoes had done almost two years, and I was starting to see my toe poking through the mesh, so I needed new ones. I’m tight and don’t like spending on this stuff, but the other week, I finally gave in.
I splashed out, and the new shoes went on last weekend. Parkrun: Nailed it.
But here’s the thing: My parkrun times have been getting quicker over time anyway. Last summer my Parkrun times were around 25mins. In January, I hit sub-24mins as a PB. Last weekend I hit sub-23. There is a trendline there.
I can’t tell you that I wouldn’t have PB’d (which is a new verb I’ve just invented), if I had kept my knackered old shoes with the toe poking out.
This is the same problem that shows up in evaluation all over. Did your intervention actually cause the thing to happen?
The problem with pre- and post-
Instinctively, we think of a simple way to compare this. Compare my parkrun time before the new shoes, to my time after. Improvement means shoe-impact.
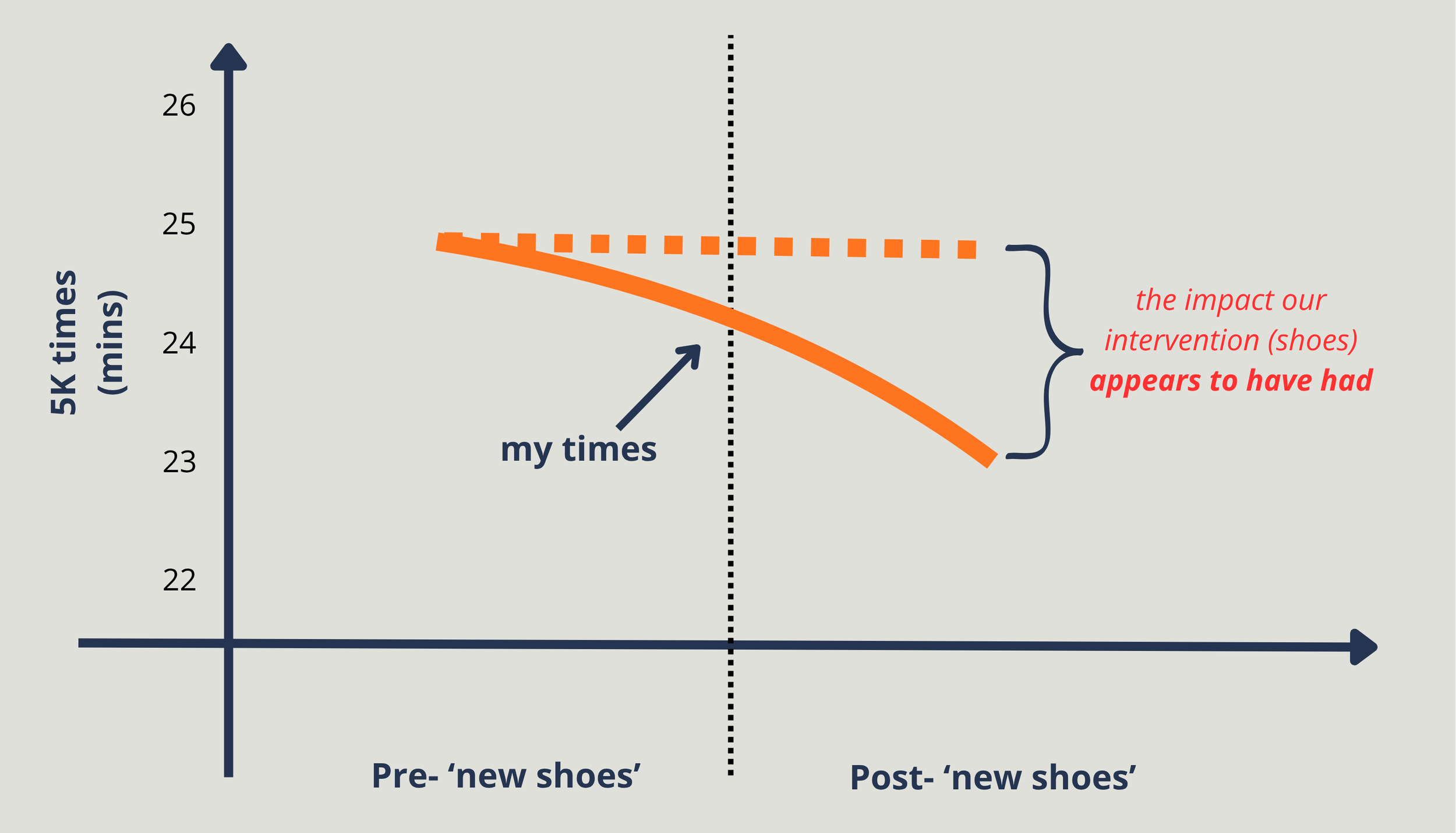
But here it isn’t giving us the full picture.
We do this too much in evaluation, and not just in running. This happens in higher education, widening participation, in the charity sector, in schools, in communities… we measure ‘before’, then we measure ‘after’, and we associate the whole difference to whatever changed.
The problem is, in a lot of cases, things were improving anyway. Kids reading in a classroom is going to get better over time. People who have a bit of a cold will probably get better anyway, despite whatever alternative treatment they think has cured them.
For me, my parkrun time has been improving anyway because I’ve been running more. So the question isn’t “have I improved?” The question has to be, “how much of that was down to the shoes?”.
The Difference in the Differences
This is where ‘Difference-in-Differences’ (or Diff-in-Diff if you’re one of the cool kids) comes in.
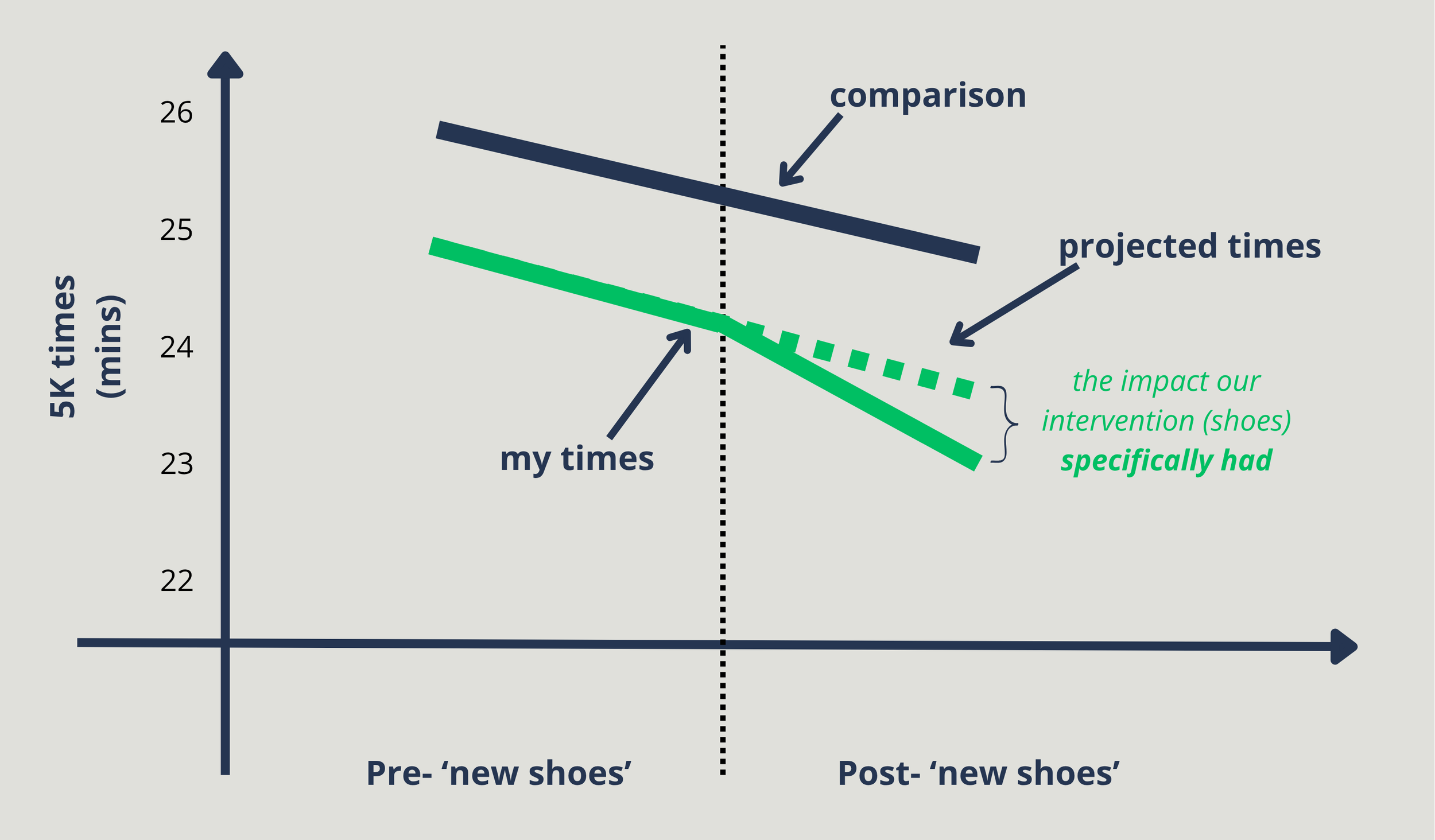
Instead of comparing my time before and after the new shoes, Diff-in-Diff asks to find someone similar to me, training over the same period who stuck with their old shoes. You then look at how much they improved over the same time, just from the training.
Their improvement = from running 3 times a week
My improvement = from running 3 times a week + new shoes
Subtract their improvement from mine, and what’s left is (in theory) the proper effect of the shoes, with the “everyone gets a bit better with regular running” effect stripped out.
This is why this method is so important.
It’s not just measuring overall change. It’s measuring the extra bit of change that your intervention has caused. That’s why it’s so important in evaluation.
So how does this look in practice…
Returning to Parkrun
I have a few friends who have also signed up for the Robin Hood Half. We’re all starting from not dissimilar levels of fitness, and try to do Parkrun most Saturdays.
But let’s imagine that there are 100 of us.
Imagine we all spend the next couple of months tracking our runs. We’re all in roughly the same time bracket, but there are differences between us for sure. But half of us get swanky new shoes.
And imagine that after several weeks, my group with the new shoes track our runs. We shave 2mins off our 5k times, on average. Imagine that over the same period, the other group (with their old standard shoes) shave 1 minute off their 5k, on average.
Collectively, we’re all improving by 1 minute, but my group is better by an extra minute. That improvement is the effect attributable to the shoes.
A change, but not the cause
Let’s imagine a slightly different scenario. Same two groups. But this time, let’s imagine that overall, everyone on average got better at the same rate. On average, we all shaved a minute off our time over a month.
I’m feeling great in my new shoes, and doing Parkrun’s quicker than ever. But the thing is, we’re all improving.
A simple pre- and post- test of getting new shoes would have shown a change. And shaving a minute off your Parkrun is a big improvement. But the Diff-in-Diff didn’t show a difference between the differences.
This happens everywhere. People measure improvement, but the improvement may well have happened anyway. Still, they claim the win.
There was a flaw with the evaluation.
Doing this for real
If you know a lot of this already, then you’ll know that my example does have issues.
One of the biggest here is that I’ve based it on two points of data: the pre-test parkrun time, and the post-test. We need lots of pre-treatment data points to know whether there actually was a trend, or whether it was just a blip.

Another is that often people improve at different rates and speeds. People improve in bursts, and then plateau, and even sometimes go backwards. It isn’t even always a reflection of the training or effort… sometimes we just have those periods of time where things don’t seem to work. Then you don’t try and suddenly smash it.
You see that one with weight-loss all the time.
The point is, you need loads of data points, and large numbers of participants to do this.
So if it is so hard, why do I think we should do this in Higher Education more…?
The conditions are ideal
Universities… in fact all areas of education… do two things.
High numbers. We have shed-loads of young people coming through it year after year, doing the same thing. Over and over again, data being stacked. We can see numbers over a trendline just through sheer volume.
Loads of data points. Universities LOVE to test the crap out of students. We test them at multiple points of the year, we measure them to death in various ways, so the data exists.
Most Widening Participation evaluation goes down the ‘pre- and post-’ / ‘before and after’ comparison, which I’ve already outlined problems with. The other thing we think of is trying to do a randomised controlled trial. We deliver to half a group, and actively say no to another.
This is really hard to do, both practically, and sometimes ethically.
Diff-in-Diff sits in the middle of this.
You don’t need to randomise, it works on the kind of longitudinal administrative or attainment data that universities have loads of anyway, and it directly addresses the problem we face in education: students are going to get better in their education anyway.
These kinds of quasi-experimental approaches are being seen more and more, but diff-in-diff in particular feels like it is being underused.
So maybe we need to get cracking on it.
Back to the start line
I have no idea whether my PB was down to the shoes, because of training, or because I just had my Weetabix that morning.
But I do know is that the question matters. Not ‘did I improve?’ but ‘how much of that improvement was down to the thing I changed?’
That’s the thing evaluation should ask for more often. In WP, in education, in social change programmes in a variety of sectors.
We can do evaluation better, without having do design really complicated RCTs or setting up experiments.
Anyway, I’m off for another jog (once this bloody heatwave calms down a bit!)